Versatile and Reconcilable approach for storing files in modern applications.
Abstract
File Storage systems are found almost in every conceivable business scenario, and a file is arguably the de-facto standard of accessing data from the storage systems. Due to the rise of cloud storage, big data technologies, and availability of divergent storage models and services for subjective use-cases, configuring applications solely to work with individual storage service (tight coupling) can result in reduced reconcilability and extensibility (integrating with external services) of the application for storing and managing data. Replacing or migrating to different storage services requires a significant amount of refactoring in the system. This paper aims to solve this problem by enabling modern applications to integrate with different storage technologies and services by using a hybrid approach for storing files. It consists of two primary components, namely the relational database, and a selected storage system or service. This paper focuses on the implementation details of the concept and compare with different approaches for doing similar work.
Abstract simple
File Storage systems are found almost in every conceivable business scenario, and a file is arguably the de-facto standard of accessing data from the storage systems. Due to the rise of cloud storage, big data technologies and the availability of divergent storage services for subjective use-cases, applications need to be able to seamlessly integrate with other storage systems and services without significant refactoring in the system. Configuring applications solely to work with individual storage service (tight coupling) can result in reduced reconcilability (able to comply with different storage systems) and extensibility (able to integrate with external services) of the application for storing and managing data. Adapting to different storage services requires a significant amount of refactoring in the system. This paper aims to solve this problem by enabling modern applications to integrate with different storage technologies and services by using a hybrid approach for storing files. This paper focuses on the implementation details of the concept and compare different approaches for doing similar work.
Definitions Abbreviations used
file - file represents a computer file or a datastructure to store wide range of data.
API - Application programming interface.
Overview of working
The core aim of RDFS is to allow modern applications to leverage all the perks of Database Management Systems (DBMS) and enable to seamlessly integrate different storage systems for their purpose implicitly without manipulating application logic and without much overhead.
It comes to no surprise that filesystems out perform databases when storing large files or data.
So RDFS encapsulates two major component that is the database and the storage system.
Database is responsible for storing all file metadata and the file structure which represents the relation between files(Storage pattern example hierarchical data). Sole job of the the storage system is to insert, manipulate and retrieve data to and from the database.
RDFS gives freedom to choose variety of different storage systems and having different storage mechanisms given that it complies to the pre-defined agreement or interface which is discussed further in detail.
Until and unless fetching or manipulating file contents is not necessary all the operations are managed by the database itself.
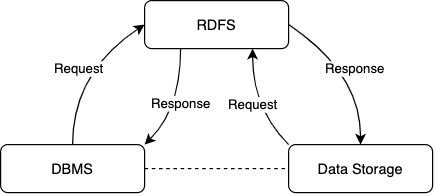
RDFS Database
Database is responsible for storage of file metadata and it's attributes as much as possible with intend to reducing unwanted load on core Storage system. These paper mentions the core schema for the database but it could be further extended as per requirements. Also additional attributes could be added as per the storage system in use. For storing data having size greater than 5MB, it is better to store in the file storage system, in other case database does fine.Even if the files are smaller in size it is preferred to store in the file system as it is easy to migrate and for backup purposes which could be independently.
Blob Vs File
It comes to no surprise that filesystems out perform databases when it comes to storing large files. When the file content size is less than 246KB it is better to store data as the blob in database. But in other case filesystem performs a lot better. This paper will concentrate more on for bigger file size storage.In case using integrated file or object storage is discussed further in detail.
Models for storing hierarchical data
Models for storing hierarchical data in relational databases namely are Adjacency List, Path Enumeration, Nested Sets, Closure Table.
The diagram gives you a generic understanding of all models. The levels easy and hard signifies the complexity involved in performing the operation, in most cases leading to performance degradation. Based on the context, employee the technique that is more relevant by looking at fig table. 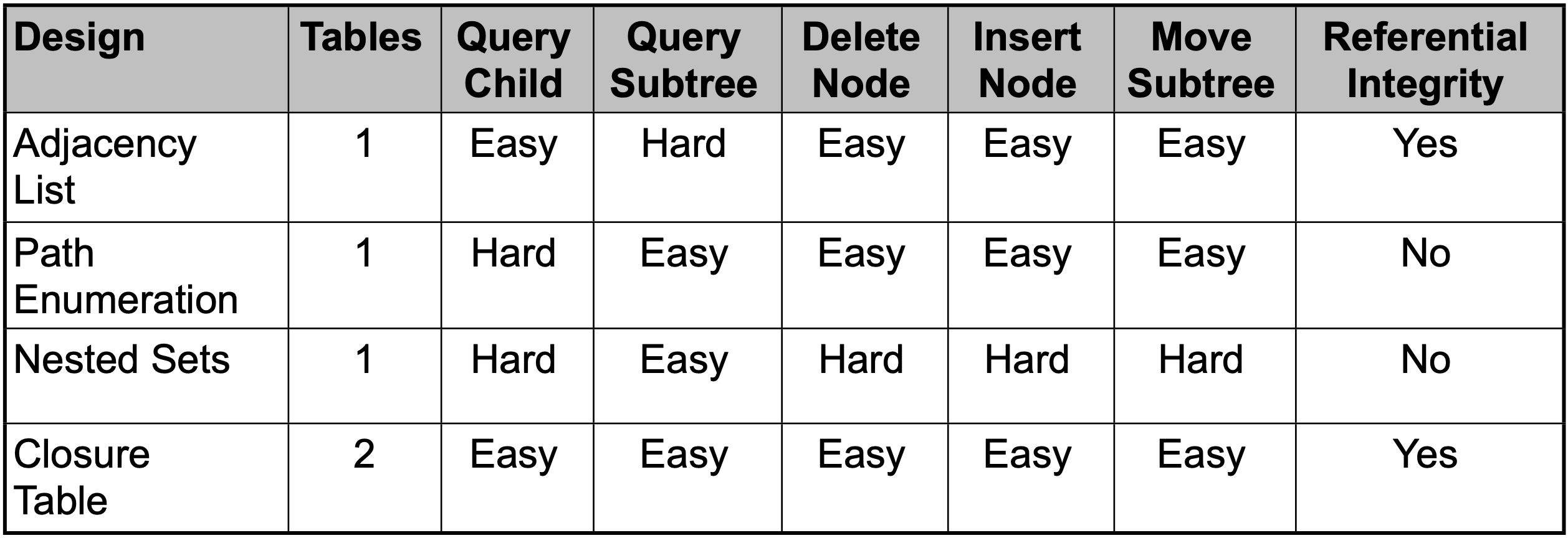
Depending on the context and demand over choosing performance, space and complexity suitable techniques could be used.
But for RDFS only Adjacency List and Closure Table can be used as they satisfy referential integrity.
Database Schema
The schema definition mainly specifies the required necessary attributes, but more attributes could be added for subjective requirements.
CREATE TABLE File(
file_id int NOT NULL PRIMARY KEY,
parent_id int REFERENCES File(file_id), /* NULL represents root directory */
file_name char(50),
file_type int NOT NULL /* Represents if row is of type file-'1' or folder-'0' */
);
- Folders are represented as files in database, they are distinguished files by the file_type attribute.
| Field | Description |
|---|---|
| File Identifier | Unique identifier assigned to each file.It is the primary key attribute for the table. |
| Parent Folder Identifier | Unique identifier for immediate parent or ancestor file of current file. Null indicates that the file or folder is in the root directory. It is optional when all the files are stored at same level in case designing a flat file system. |
| File Name | Name assigned to the file. |
| File Type | Indicates if the node is of type file or a folder. In this case '1' represents a file and '0' represents a folder in hierarchy. |
| File Size | File size can be stored in database for faster retrieval (optional). |
| File Location (Pointer to memory location) | File location is used pointing address of file contents in the selected storage system used.It is essential when using object or block storage where the attribute represents object_id or the address pointer for the starting address of the block. |
Adjacency List
This is basically a naive approach for managing hierarchical data. In this model each entry knows it's immediate parent. This states the each file has a reference to associated folder identifier to which it belongs. Adjacency model also enable multiple folders to point to the same file if required.
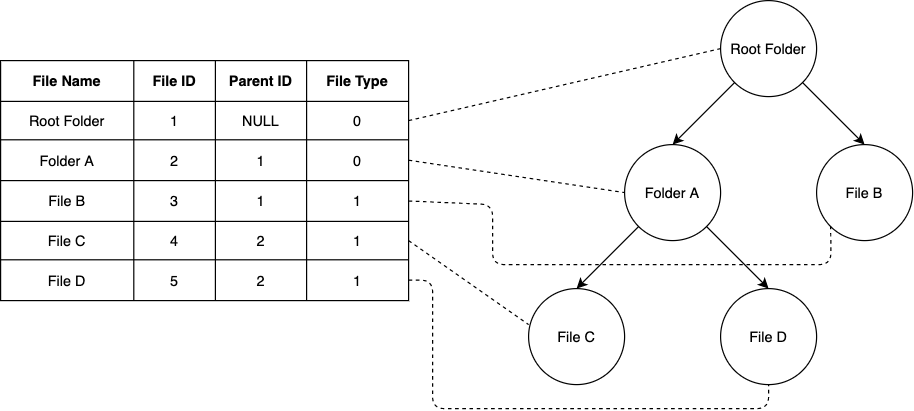
Further Adjacency List could also be used with Common Table Expressions for supporting recursive queries for fetching subtree or the whole tree structure from the database. It comes handy when you want to constrain the level of nesting and also keep track of the nodes. And also suitable schema definition for relational DBMS supporting horizontal scaling.
Pros Insert Delete move operations are great Cons Can't handle deep trees.
Closure Table
It is similar to the many to many relationships in relational databases. Each parent folder has a relation with all it's descendants to further understand it is well illustrated in the figure given below. A node even connects to itself. Stores every path from each node to each of its descendants. 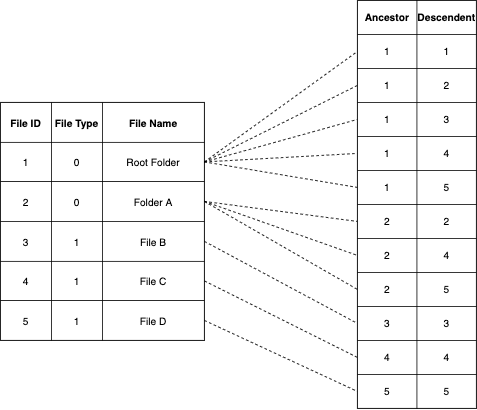
Pros Cons
Operations
When it comes to performing file operation algorithm both storage models i.e Adjacency List and Closure Table closely similar. The Algorithm for essential file operations are stated below.
Operations -
- Searching a file - Search the file in the database using the select operation where the file identifier is matched. If matched then return as result-set.
- Getting parent folder of specified file - Parent folder can be found using parent identifier attribute of the specified file.
- Getting files belonging to specified folder - It can be done by fetching all intermediate descendants or files where parent or ancestor is same as that of specified folder.Repeat the process recursively for each descendant until the leaf node representing a file.
- Getting whole directory structure- It is same as getting the descendants of a specified folder considering the root directory as the parent folder.
- Create new file - Creating a new file that requires inserting of the created file into the database after the file contents are uploaded or persisted in underlying storage system.
- Delete file - Deleting a file requires removing file-contents from the storage and deleting the record of respective file. For soft deletes only mark the file tuple with flag indicating that the file is been deleted and removed from the system.
- Move file - If the file structure and relations are maintained by the database itself the only updating the file parent attribute does the job. In other cases it may require another call to storage for necessary updations.
Implementation for Adjacency List
Write Operations
- Searching a file - Searching a file named "File D".
SELECT * from File where file_name like "File D";
- Getting parent folder a file - Searching for record with identity same as associated parent id with the file.
Select * from File where file_type=0 and file_id in (SELECT parent_id from File where file_name like "File D" limit 1);
- Creating new file - To make an record in the database after storing the file contents.
INSERT into File (file_name,parent_id,file_type) values ("File E",2,1);
- Creating new folder - To make an record in the database after storing the file contents.
INSERT into File (file_name,parent_id,file_type) values ("Folder F",2,0);
- Move a file or folder- To make an record in the database after storing the file contents.
UPDATE File SET parent_id = 1 where file_id = 6;
Read Operations
- Query intermediate children or files - To make an record in the database after storing the file contents.
Select * from File where File.parent_id = 1 and file_type=1;
- Query subtree - To make an record in the database after storing the file contents.
Select * from File where File.parent_id = 1 and file_type=1;
- Query whole tree- To make an record in the database after storing the file contents.
Select * from File where File.parent_id = 1 and file_type=1;
Indexing for performance
Using indexes could have a significant impact on the performance of major file operations that involves searching and accessing file records from the database.
A database index is a data structure that improves the speed of data retrieval operations on a database table at the cost of additional writes and storage space to maintain the index data structure. Indexes are used to quickly locate data without having to search every row in a database table every time a database table is accessed. Indexes can be created using one or more columns of a database table, providing the basis for both rapid random lookups and efficient access of ordered records.[Wikipedia]
An index is a copy of selected columns of data from a table, called a database key or simply key, that can be searched very efficiently that also includes a low-level disk block address or direct link to the complete row of data it was copied from.
Most database software includes indexing technology that enables sub-linear time lookup to improve performance, as linear search is inefficient for large databases.
Suppose a database contains N files and one must be retrieved based on the value of unique file identifier. A simple implementation retrieves and examines each file. If there is only one matching file, this can stop when it finds the desired file, but if there are multiple matches, it must look to every file in the system. This means that the number of operations in the average case is O(N) or linear time. Since databases may contain many files, and since lookup is a common operation, it is often desirable to improve performance. An index is any data structure that improves the performance of lookup. There are many different data structures used for this purpose. There are complex design trade-offs involving lookup performance, index size, and index-update performance. Many index designs exhibit logarithmic (O(log(N))) lookup performance and in some applications it is possible to achieve flat (O(1)) performance. For our purposes any index exhibiting logarithmic lookup performance or faster will work fine. So creating index on file identifiers will result in significantly faster performance as it is most frequently accessed.
Storage System Filesystems
As storing all the structural and metadata content in the databases gives more flexibility to integrate heterogeneous storage systems for required and subjective type of storage. Storage system typically a file system or object storage system designed to effectively scale and to store large data.
- Different storage schemes also custom may work!
Dependency Injection
- What is the problem we are trying to solve
As the main motive is to easily switch between different storage systems these module needs to be loosely coupled with the system. As all the essential and metadata is being stored in a database so the storage system solely needs to handle the file contents. In order to communicate with any storage service, the storage has it's own API (Application Programming Interface) which allows external systems to integrate with the storage service.
And it is also crucial to ensure that the selected storage service supports and complies with the requirements of application or system(RDFS).
For integrating these heterogeneous storage system dependency injection enables loose coupling between two components.This enables RDFS to rely on dependencies and this dependency could replace easily if it meets certain constraints. In order to enforce some integrity constraints interface could be defined.
So how can we make this possible?. DI.
- What is DI
Dependency injection is one form of the broader technique of inversion of control. A client who wants to call some services should not have to know how to construct those services. Instead, the client delegates the responsibility of providing its services to external code (the injector). The client is not allowed to call the injector code;[3] it is the injector that constructs the services. The injector then injects (passes) the services into the client which might already exist or may also be constructed by the injector. The client then uses the services. This means the client does not need to know about the injector, how to construct the services, or even which actual services it is using. The client only needs to know about the intrinsic interfaces of the services because these define how the client may use the services. This separates the responsibility of "use" from the responsibility of "construction".
Dependency injection frameworks
Many application frameworks are available to support dependency injection, but they are not required or necessary to do dependency injection.[20][21]
- Techniques Diagram
Application delegates all the responsibilities relating to storing file content to the injector i.e the storage object which in turn points to the actual service used. So if underlying storage system is to be changed, the behaviour between the application and the database object remains the same, so no code refactoring changes have to be done in the application itself.
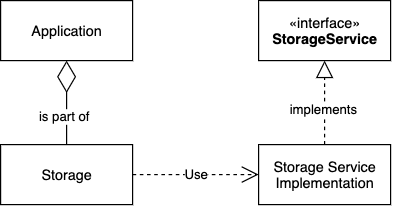
As the storage object is a part of the application which relies on the storage service module to perform its task.
- How can we implement
But to ensure that the storage service supports the intrinsic behaviour the client expects the StorageService controller class has to implement the StorageService interface defined by the application itself.
This allows the storage service to comply with different heterogeneous data sources.
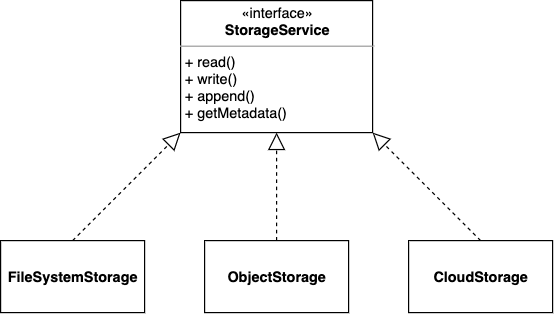
- Multiple injectors
It also gives you the flexibility to store data in multiple data sources and also come with custom storage architecture. It could easily extent the application support to add for backend data warehouse for OLAP operations to work with OLTP systems simultaneously. So it obviates the use of HTAP Data stores. It could also enable for multi-cloud storage systems as well.
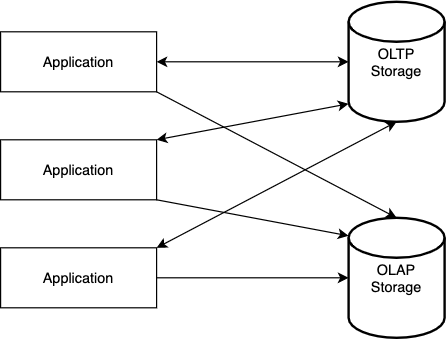
It also gives you the flexibility to store data in multiple data sources and also come with custom storage architecture. It could easily extent the application support to add for backend data warehouse for OLAP operations to work with OLTP systems simultaneously. So it obviates the use of HTAP Data stores. It could also enable for multi-cloud storage systems as well.
Advantages of DI
- Dependency injection allows a client the flexibility of being configurable. Only the client's behavior is fixed. The client may act on anything that supports the intrinsic interface the client expects.[22]
- Dependency injection can be used to externalize a system's configuration details into configuration files, allowing the system to be reconfigured without recompilation. Separate configurations can be written for different situations that require different implementations of components. This includes, but is not limited to, testing.[23]
- Because dependency injection does not require any change in code behavior it can be applied to legacy code as a refactoring. The result is clients that are more independent and that are easier to unit test in isolation using stubs or mock objects that simulate other objects not under test. This ease of testing is often the first benefit noticed when using dependency injection.[24]
- Dependency injection allows a client to remove all knowledge of a concrete implementation that it needs to use. This helps isolate the client from the impact of design changes and defects. It promotes reusability, testability and maintainability.[25]
- Reduction of boilerplate code in the application objects, since all work to initialize or set up dependencies is handled by a provider component.[25]
- Dependency injection allows concurrent or independent development. Two developers can independently develop classes that use each other, while only needing to know the interface the classes will communicate through. Plugins are often developed by third party shops that never even talk to the developers who created the product that uses the plugins.[26]
- Dependency Injection decreases coupling between a class and its dependency.
Disadvantages of DI
- Dependency injection creates clients that demand configuration details be supplied by construction code. This can be onerous when obvious defaults are available.[29]
- Dependency injection can make code difficult to trace (read) because it separates behavior from construction. This means developers must refer to more files to follow how a system performs.[30]
- Dependency injection frameworks are implemented with reflection or dynamic programming. This can hinder use of IDE automation, such as "find references", "show call hierarchy" and safe refactorings.[31]
- Dependency injection typically requires more upfront development effort since one can not summon into being something right when and where it is needed but must ask that it be injected and then ensure that it has been injected.[32]
- Dependency injection forces complexity to move out of classes and into the linkages between classes which might not always be desirable or easily managed.[33]
- Dependency injection can encourage dependence on a dependency injection framework.
Interfacing heterogeneous storage systems
Why Random access files in first place
Object Storage
Object storage (also known as object-based storage[1]) is a computer data storage architecture that manages data as objects, as opposed to other storage architectures like file systems which manages data as a file hierarchy, and block storage which manages data as blocks within sectors and tracks.[2] Each object typically includes the data itself, a variable amount of metadata, and a globally unique identifier. Object storage can be implemented at multiple levels, including the device level (object-storage device), the system level, and the interface level. In each case, object storage seeks to enable capabilities not addressed by other storage architectures, like interfaces that can be directly programmable by the application, a namespace that can span multiple instances of physical hardware, and data-management functions like data replication and data distribution at object-level granularity.
Object storage systems allow retention of massive amounts of unstructured data. Object storage is used for purposes such as storing photos on Facebook, songs on Spotify, or files in online collaboration services, such as Dropbox.
Though object storage is a relatively new idea for a lot of IT professionals, its benefits are mounting. Compared to traditional file systems, there are many reasons to consider an object-based system to store your data. Here are four of them:
- Scalability Object storage is known for its compatibility with cloud computing, and that’s because of its unlimited scalability. Thanks to its flat structure, object storage doesn’t have the same limitations as file or block storage. Hierarchical systems often experience complications when it comes to scaling out. Those difficulties are avoided in an object storage environment because the system scales out by adding nodes. Object storage can easily scale data to petabytes without restrictions.
Though it has these advantages in scalability, it doesn’t mean object storage systems can’t also benefit static data. In fact, object-based storage is optimal for that type of data. For this reason, object storage has a sort of niche in the market, best serving static yet scalable archival storage, according to ComputerWeekly.com. For example, object storage could be ideal for digital archives. This storage system allows faster
Faster Data Retrieval and Better Recovery Each object in the storage environment has its own identifying details, comprised of metadata and ID number, which the OS reads to retrieve data. Without the need to sift through file structures, retrieval is much faster. Thanks to the metadata and ID numbers, users don’t need to know an object’s exact location to retrieve it. TechTarget compares this process to valet parking. You don’t know where your car is parked, or if and how many times it moves throughout the evening, but by having a receipt, you’ll be able to retrieve your car at the end of the night. Having unrestricted metadata also allows storage administrators to implement their own policies for data preservation, retention and deletion. This, along with the way storage nodes are distributed across the structure, makes it easier to reinforce data and create better “disaster recovery” strategies.
Fewer Limitations Compared to the traditional file or block-based systems, object storage is far less limited because it’s not organized in a hierarchy. Because of its flat data environment, object storage provides a kind of access that other storage systems can’t allow. TechTarget also points out that the metadata in file systems is limited to file attributes, whereas in object storage, it can be customized by any number of attributes. It’s only possible to achieve that in file systems through a separate application. In addition to these advantages, as well as its unrestricted scalability, this all chalks up to a kind of limitless storage system that files or blocks can’t provide.
Cost-effectiveness For organizations who need to store large amounts of data, an object-based system could be the most cost-effective. Because it scales out much easier than other storage environments, it’s less costly to store all your data. Plus, if users have a private cloud space, costs can be even lower. Plus, compared to other systems that are considered inexpensive for these volumes of data, it’s a much more durable alternative.
Using Object Storage Service
Talk about one level file system
NOSQL Databases
NoSql databases are known for scalability factor. And the file structure and metadata could also be stored in NoSql systems due to subjective requirements.
Key-Value Stores Json Storage.
why not orm or jdbc!!!
block - object - file
Advantages
- Less load while IO on db
- Loosely coupled
- Extensible using other storage like HDFS S3 Swift etc
- Easy backups
- Easy adaptivity for diff storage systems
- Enabling communication between two heterogeneous systems
- Multiple Write Sources
- Good for writes
- Okayish for reads
- Good for OLTP
- External work for compaction and also add deduplication of data
- Easy to migrate. ##Disadvantages
Future Scope
SSD over HDD for random access memory performance is wrong
References
https://arxiv.org/pdf/cs/0701168.pdf
https://www.slideshare.net/billkarwin/models-for-hierarchical-data?from_action=save
https://etd.auburn.edu/bitstream/handle/10415/4964/wang_final.pdf;sequence=2
https://www.iitg.ac.in/awekar/teaching/cs344fall11/lecturenotes/october%2010.pdf
Amazon S3 Rest Api https://docs.aws.amazon.com/AmazonS3/latest/API/API_Operations.html